
Три в одном, или Как мы переехали в новый ЦОД, обновили ПО и сделали Disaster Recovery
Как мы собирались переезжать, а заодно обновляться
Наша компания владеет крупной сетью автозаправок. Большая часть IT-инфраструктуры организована в облаках по принципу IaaS, с распределенной сетью точек продаж и несколькими площадками в разных ЦОД.
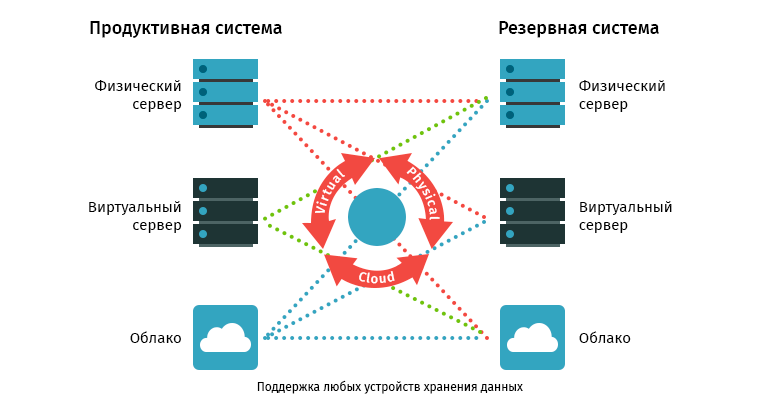
И вот у нас появилась задача слить несколько площадок в одну. Хорошо, что нам не надо было перевозить физические сервера — мы бы с ума сошли с инвентаризацией, резервными копиями, демонтажом и тестированием на новом месте.
В нашем случае речь шла только про переезд IaaS и объединение основных серверов на одной площадке. То есть провайдер предоставляет, а компания использует (не забывая вовремя платить). Например, можно перевезти только образы виртуальных машин и развернуть их на новом месте. Можно пойти еще дальше и перевезти только данные: дампы баз данных, содержимое файл-сервера и так далее. При этом оборудование на старом месте можно не отключать, сервисы не останавливать и в случае, если что-то пошло не так, временно вернуться к тому, что было ранее.
Звучит, как сказка? Да, потому что в реальности всегда найдутся подводные камни, и у нас это оказался «тонкий» канал между старыми площадками (далее для удобства мы будем обобщенно называть их ЦОД 1) и новой площадкой (ЦОД 2). 100 Мбит для переноса нашего объема данных было недостаточно, тянуть данные пришлось бы месяцами. Расширять канал мы не могли из-за технических ограничений ЦОД и интернет-провайдера. А поскольку на переносимых площадках располагались основные бизнес-сервисы, downtime должен был быть минимальным.
Кроме того, на прежних площадках использовалось старое ПО. Поэтому решили объять необъятное за один переезд, обновить версии ПО и перевести сервисы на другую площадку.
Подробности читайте в мегапосте на сайте Хабр
"Три в одном, или Как мы переехали в новый ЦОД, обновили ПО и сделали Disaster Recovery"
Новости
Смотреть все →